大家好,我是飞哥!
Linux 中的 veth 是一对儿能互相连接、互相通信的虚拟网卡。通过使用它,我们可以让 Docker 容器和母机通信,或者是在两个 Docker 容器中进行交流。参见《轻松理解 Docker 网络虚拟化基础之 veth 设备!》。

不过在实际中,我们会想在一台物理机上我们虚拟出来几个、甚至几十个的容器,以求得充分压榨物理机的硬件资源。但这样带来的问题是大量的容器之间的网络互联。很明显上面简单的 veth 互联方案是没有办法直接工作的,我们该怎么办???
回头想一下,在物理机的网络环境中,多台不同的物理机之间是如何连接一起互相通信的呢? 没错,那就是以太网交换机。同一网络内的多台物理机通过交换机连在一起,然后它们就可以相互通信了。

在我们的网络虚拟化环境里,和物理网络中的交换机一样,也需要这样的一个软件实现的设备。它需要有很多个虚拟端口,能把更多的虚拟网卡连接在一起,通过自己的转发功能让这些虚拟网卡之间可以通信。
在 Linux 下这个软件实现交换机的技术就叫做 bridge(再强调下,这是纯软件实现的)。

各个 Docker 容器都通过 veth 连接到 bridge 上,bridge 负责在不同的“端口”之间转发数据包。这样各个 Docker 之间就可以互相通信了!
今天我们来展开聊聊 bridge 的详细工作过程。
一、如何使用 bridge
在分析它的工作原理之前,很有必要先来看一看网桥是如何使用的。
为了方便大家理解,接下来我们通过动手实践的方式,在一台 Linux 上创建一个小型的虚拟网络出来,并让它们之间互相通信。
1.1 创建两个不同的网络
Bridge 是用来连接两个不同的虚拟网络的,所以在准备实验 bridge 之前我们得先需要用 net namespace 构建出两个不同的网络空间来。

具体的创建过程如下。我们通过 ip netns 命令创建 net namespace。首先创建一个 net1:
# ip netns add net1接下来创建一对儿 veth 出来,设备名分别是 veth1 和 veth1_p。并把其中的一头 veth1 放到这个新的 netns 中。
# ip link add veth1 type veth peer name veth1_p
# ip link set veth1 netns net1因为我们打算是用这个 veth1 来通信,所以需要为其配置上 ip,并把它启动起来。
# ip netns exec net1 ip addr add 192.168.0.101/24 dev veth1
# ip netns exec net1 ip link set veth1 up查看一下,上述的配置是否成功。
# ip netns exec net1 ip link list
# ip netns exec net1 ifconfig重复上述步骤,在创建一个新的 netns出来,命名分别为。
- netns: net2
- veth pair: veth2, veth2_p
- ip: 192.168.0.102
好了,这样我们就在一台 Linux 就创建出来了两个虚拟的网络环境。
1.2 把两个网络连接到一起
在上一个步骤中,我们只是创建出来了两个独立的网络环境而已。这个时候这两个环境之间还不能互相通信。我们需要创建一个虚拟交换机 - bridge, 来把这两个网络环境连起来。

创建过程如下。创建一个 bridge 设备, 把刚刚创建的两对儿 veth 中剩下的两头“插”到 bridge 上来。
# brctl addbr br0
# ip link set dev veth1_p master br0
# ip link set dev veth2_p master br0
# ip addr add 192.168.0.100/24 dev br0再为 bridge 配置上 IP,并把 bridge 以及插在其上的 veth 启动起来。
# ip link set veth1_p up
# ip link set veth2_p up
# ip link set br0 up查看一下当前 bridge 的状态,确认刚刚的操作是成功了的。
# brctl show
bridge name bridge id STP enabled interfaces
br0 8000.4e931ecf02b1 no veth1_p
veth2_p1.3 网络连通测试
激动人心的时刻就要到了,我们在 net1 里(通过指定 ip netns exec net1 以及 -I veth1),ping 一下 net2 里的 IP(192.168.0.102)试试。

# ip netns exec net1 ping 192.168.0.102 -I veth1
PING 192.168.0.102 (192.168.0.102) from 192.168.0.101 veth1: 56(84) bytes of data.
64 bytes from 192.168.0.102: icmp_seq=1 ttl=64 time=0.037 ms
64 bytes from 192.168.0.102: icmp_seq=2 ttl=64 time=0.008 ms
64 bytes from 192.168.0.102: icmp_seq=3 ttl=64 time=0.005 ms哇塞,通了通了!!
这样,我们就在一台 Linux 上虚拟出了 net1 和 net2 两个不同的网络环境。我们还可以按照这种方式创建更多的网络,都可以通过一个 bridge 连接到一起。这就是 Docker 中网络系统工作的基本原理。
二、Bridge 是如何创建出来的
在内核中,bridge 是由两个相邻存储的内核对象来表示的。

我们先看下它是如何被创建出来的。内核中创建 bridge 的关键代码在 br_add_bridge 这个函数里。
//file:net/bridge/br_if.c
int br_add_bridge(struct net *net, const char *name)
{
//申请网桥设备,并用 br_dev_setup 来启动它
dev = alloc_netdev(sizeof(struct net_bridge), name,
br_dev_setup);
dev_net_set(dev, net);
dev->rtnl_link_ops = &br_link_ops;
//注册网桥设备
res = register_netdev(dev);
if (res)
free_netdev(dev);
return res;
}上述代码中注册网桥的关键代码是 alloc_netdev 这一行。在这个函数里,将申请网桥的内核对象 net_device。在这个函数调用里要注意两点。
- 1.第一个参数传入了 struct net_bridge 的大小
- 2.第三个参数传入的 br_dev_setup 是一个函数。
带着这两点注意事项,我们进入到 alloc_netdev 的实现中。
//file: include/linux/netdevice.h
#define alloc_netdev(sizeof_priv, name, setup) \
alloc_netdev_mqs(sizeof_priv, name, setup, 1, 1)好吧,竟然是个宏。那就得看 alloc_netdev_mqs 了。
//file: net/core/dev.c
struct net_device *alloc_netdev_mqs(int sizeof_priv, ...,void (*setup)(struct net_device *))
{
//申请网桥设备
alloc_size = sizeof(struct net_device);
if (sizeof_priv) {
alloc_size = ALIGN(alloc_size, NETDEV_ALIGN);
alloc_size += sizeof_priv;
}
p = kzalloc(alloc_size, GFP_KERNEL);
dev = PTR_ALIGN(p, NETDEV_ALIGN);
//网桥设备初始化
dev->... = ...;
setup(dev); //setup是一个函数指针,实际使用的是 br_dev_setup
...
}在上述代码中。kzalloc 是用来在内核态申请内核内存的。需要注意的是,申请的内存大小是一个 struct net_device 再加上一个 struct net_bridge(第一个参数传进来的)。一次性就申请了两个内核对象,这说明bridge 在内核中是由两个内核数据结构来表示的,分别是 struct net_device 和 struct net_bridge。
申请完了一家紧接着调用 setup,这实际是外部传入的 br_dev_setup 函数。在这个函数内部进行进一步的初始化。
//file: net/bridge/br_device.c
void br_dev_setup(struct net_device *dev)
{
struct net_bridge *br = netdev_priv(dev);
dev->... = ...;
br->... = ...;
...
}总之,brctl addbr br0 命令主要就是完成了 bridge 内核对象(struct net_device 和 struct net_bridge)的申请以及初始化。
三、添加设备
调用 brctl addif br0 veth0 给网桥添加设备的时候,会将 veth 设备以虚拟的方式连到网桥上。当添加了若干个 veth 以后,内核中对象的大概逻辑图如下。

其中 veth 是由 struct net_device来表示,bridge 的虚拟插口是由 struct net_bridge_port 来表示。我们接下来看看源码,是如何达成上述的逻辑结果的。
添加设备会调用到 net/bridge/br_if.c 下面的 br_add_if。
//file: net/bridge/br_if.c
int br_add_if(struct net_bridge *br, struct net_device *dev)
{
// 申请一个 net_bridge_port
struct net_bridge_port *p;
p = new_nbp(br, dev);
// 注册设备帧接收函数
err = netdev_rx_handler_register(dev, br_handle_frame, p);
// 添加到 bridge 的已用端口列表里
list_add_rcu(&p->list, &br->port_list);
......
}这个函数中的第二个参数 dev 传入的是要添加的设备。在本文中,就可以认为是 veth 的其中一头。比较关键的是 net_bridge_port 这个结构体,它模拟的是物理交换机上的一个插口。它起到一个连接的作用,把 veth 和 bridge 给连接了起来。见 new_nbp 源码如下:
//file: net/bridge/br_if.c
static struct net_bridge_port *new_nbp(struct net_bridge *br,
struct net_device *dev)
{
//申请插口对象
struct net_bridge_port *p;
p = kzalloc(sizeof(*p), GFP_KERNEL);
//初始化插口
index = find_portno(br);
p->br = br;
p->dev = dev;
p->port_no = index;
...
}在 new_nbp 中,先是申请了代表插口的内核对象。find_portno 是在当前 bridge 下寻找一个可用的端口号。接下来插口对象通过 p->br = br 和 bridge 设备关联了起来,通过 p->dev = dev 和代表 veth 设备的 dev 对象也建立了联系。
在 br_add_if 中还调用 netdev_rx_handler_register 注册了设备帧接收函数,设置 veth 上的 rx_handler 为 br_handle_frame。后面在接收包的时候会回调到它。
//file:
int netdev_rx_handler_register(struct net_device *dev,
rx_handler_func_t *rx_handler,
void *rx_handler_data)
{
...
rcu_assign_pointer(dev->rx_handler_data, rx_handler_data);
rcu_assign_pointer(dev->rx_handler, rx_handler);
}四、数据包处理过程
在图解Linux网络包接收过程中我们讲到过接收包的完整流程。数据包会被网卡先送到 RingBuffer 中,然后依次经过硬中断、软中断处理。在软中断中再依次把包送到设备层、协议栈,最后唤醒应用程序。
不过,拿 veth 设备来举例,如果它连接到了网桥上的话,在设备层的 \_\_netif_receive_skb_core 函数中和上述过程有所不同。连在 bridge 上的 veth 在收到数据包的时候,不会进入协议栈,而是会进入网桥处理。网桥找到合适的转发口(另一个 veth),通过这个 veth 把数据转发出去。工作流程如下图。

我们从 veth1_p 设备的接收看起,所有的设备的接收都一样,都会进入 \_\_netif_receive_skb_core 设备层的关键函数。
//file: net/core/dev.c
static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc)
{
...
// tcpdump 抓包点
list_for_each_entry_rcu(...);
// 执行设备的 rx_handler(也就是 br_handle_frame)
rx_handler = rcu_dereference(skb->dev->rx_handler);
if (rx_handler) {
switch (rx_handler(&skb)) {
case RX_HANDLER_CONSUMED:
ret = NET_RX_SUCCESS;
goto unlock;
}
}
// 送往协议栈
//...
unlock:
rcu_read_unlock();
out:
return ret;
}在 \_\_netif_receive_skb_core 中先是过了 tcpdump 的抓包点,然后查找和执行了 rx_handler。在上面小节中我们看到,把 veth 连接到网桥上的时候,veth 对应的内核对象 dev 中的 rx_handler 被设置成了 br_handle_frame。所以连接到网桥上的 veth 在收到包的时候,会将帧送入到网桥处理函数 br_handle_frame 中。
另外要注意的是网桥函数处理完的话,一般来说就 goto unlock 退出了。和普通的网卡数据包接收相比,并不会往下再送到协议栈了。
接着来看下网桥是咋工作的吧,进入到 br_handle_frame 中来搜寻。
//file: net/bridge/br_input.c
rx_handler_result_t br_handle_frame(struct sk_buff **pskb)
{
...
forward:
NF_HOOK(NFPROTO_BRIDGE, NF_BR_PRE_ROUTING, skb, skb->dev, NULL,
br_handle_frame_finish);
}上面我对 br_handle_frame 的逻辑进行了充分的简化,简化后它的核心就是调用 br_handle_frame_finish。同样 br_handle_frame_finish 也有点小复杂。本文中,我们主要想了解的 Docker 场景下 bridge 上的 veth 设备转发。所以根据这个场景,我又对该函数进行了充分的简化。
//file: net/bridge/br_input.c
int br_handle_frame_finish(struct sk_buff *skb)
{
// 获取 veth 所连接的网桥端口、以及网桥设备
struct net_bridge_port *p = br_port_get_rcu(skb->dev);
br = p->br;
// 更新和查找转发表
struct net_bridge_fdb_entry *dst;
br_fdb_update(br, p, eth_hdr(skb)->h_source, vid);
dst = __br_fdb_get(br, dest, vid)
// 转发
if (dst) {
br_forward(dst->dst, skb, skb2);
}
}在硬件中,交换机和集线器的主要区别就是它会智能地把数据送到正确的端口上去,而不会像集线器那样给所有的端口都群发一遍。所以在上面的函数中,我们看到了更新和查找转发表的逻辑。这就是网桥在学习,它会根据它的自学习结果来工作。
在找到要送往的端口后,下一步就是调用 br_forward => \_\_br_forward 进入真正的转发流程。
//file: net/bridge/br_forward.c
static void __br_forward(const struct net_bridge_port *to, struct sk_buff *skb)
{
// 将 skb 中的 dev 改成新的目的 dev
skb->dev = to->dev;
NF_HOOK(NFPROTO_BRIDGE, NF_BR_FORWARD, skb, indev, skb->dev,
br_forward_finish);
}在 \_\_br_forward 中,将 skb 上的设备 dev 改为了新的目的 dev。

然后调用 br_forward_finish 进入发送流程。 在 br_forward_finish 里会依次调用 br_dev_queue_push_xmit、dev_queue_xmit。
//file: net/bridge/br_forward.c
int br_forward_finish(struct sk_buff *skb)
{
return NF_HOOK(NFPROTO_BRIDGE, NF_BR_POST_ROUTING, skb, NULL, skb->dev,
br_dev_queue_push_xmit);
}
int br_dev_queue_push_xmit(struct sk_buff *skb)
{
dev_queue_xmit(skb);
...
}dev_queue_xmit 就是发送函数,在上一篇《轻松理解 Docker 网络虚拟化基础之 veth 设备!》中我们介绍过,后续的发送过程就是 dev_queue_xmit => dev_hard_start_xmit => veth_xmit。 在 veth_xmit 中会获取到当前 veth 的对端,然后把数据给它发送过去。

至此,bridge 上的转发流程就算是完毕了。要注意到的是,整个 bridge 的工作的源码都是在 net/core/dev.c 或 net/bridge 目录下。都是在设备层工作的。这也就充分印证了我们经常说的 bridge(物理交换机也一样) 是二层上的设备。
接下来,收到网桥发过来数据的 veth 会把数据包发送给它的对端 veth2,veth2再开始自己的数据包接收流程。
)
五、总结
所谓网络虚拟化,其实用一句话来概括就是用软件来模拟实现真实的物理网络连接。
Linux 内核中的 bridge 模拟实现了物理网络中的交换机的角色。和物理网络类似,可以将虚拟设备插入到 bridge 上。不过和物理网络有点不一样的是,一对儿 veth 插入 bridge 的那端其实就不是设备了,可以理解为退化成了一个网线插头。
当 bridge 接入了多对儿 veth 以后,就可以通过自身实现的网络包转发的功能来让不同的 veth 之间互相通信了。
回到 Docker 的使用场景上来举例,完整的 Docker 1 和 Docker 2 通信的过程是这样的:

大致步骤是:
- 1.Docker1 往 veth1 上发送数据
- 2.由于 veth1_p 是 veth1 的 pair, 所以这个虚拟设备上可以收到包
- 3.veth 收到包以后发现自己是连在网桥上的,于是乎进入网桥处理。在网桥设备上寻找要转发到的端口,这时找到了 veth2_p 开始发送。网桥完成了自己的转发工作
- 4.veth2 作为 veth2_p 的对端,收到了数据包
- 5.Docker2 里的就可以从 veth2 设备上收到数据了
觉得这个流程图还不过瘾?那我们再继续拉大视野,从两个 Docker 的用户态来开始看一看。

Docker 1 在需要发送数据的时候,先通过 send 系统调用发送,这个发送会执行到协议栈进行协议头的封装等处理。经由邻居子系统找到要使用的设备(veth1)后,从这个设备将数据发送出去,veth1 的对端 veth1_p 会收到数据包。
收到数据的 veth1_p 是一个连接在 bridge 上的设备,这时候 bridge 会接管该 veth 的数据接收过程。从自己连接的所有设备中查找目的设备。找到 veth2_p 以后,调用该设备的发送函数将数据发送出去。同样 veth2_p 的对端 veth2 即将收到数据。
其中 veth2 收到数据后,将和 lo、eth0 等设备一样,进入正常的数据接收处理过程。Docker 2 中的用户态进程将能够收到 Docker 1 发送过来的数据了就。
怎么样,今天你有没有更深入地理解了 Docker 的工作原理呢?最后转发到朋友圈,让你的朋友们也一起来学学吧~~~
写在最后,由于我的这些知识在公众号里文章比较分散,很多人似乎没有理解到我对知识组织的体系结构。而且图文也不像视频那样理解起来更直接。所以我在知识星球上规划了视频系列课程,包括硬件原理、内存管理、进程管理、文件系统、网络管理、Golang语言、容器原理、性能观测、性能优化九大部分大约 120 节内容,每周更新。加入方式参见我要开始搞知识星球啦、如何才能高效地学习技术,我投“融汇贯通”一票
Github:https://github.com/yanfeizhang/coder-kung-fu
关注公众号:微信扫描下方二维码
我打造了一套更为完整的视频课程。总共包括了硬件原理、内存管理、进程管理、网络管理、文件系统、容器原理、性能观测、性能优化、调用原理、等几个大部分的内容。
其中有 5 个大部分已经更新完毕,下图中彩色部分为已更新内容,总时长 1900 多分钟。
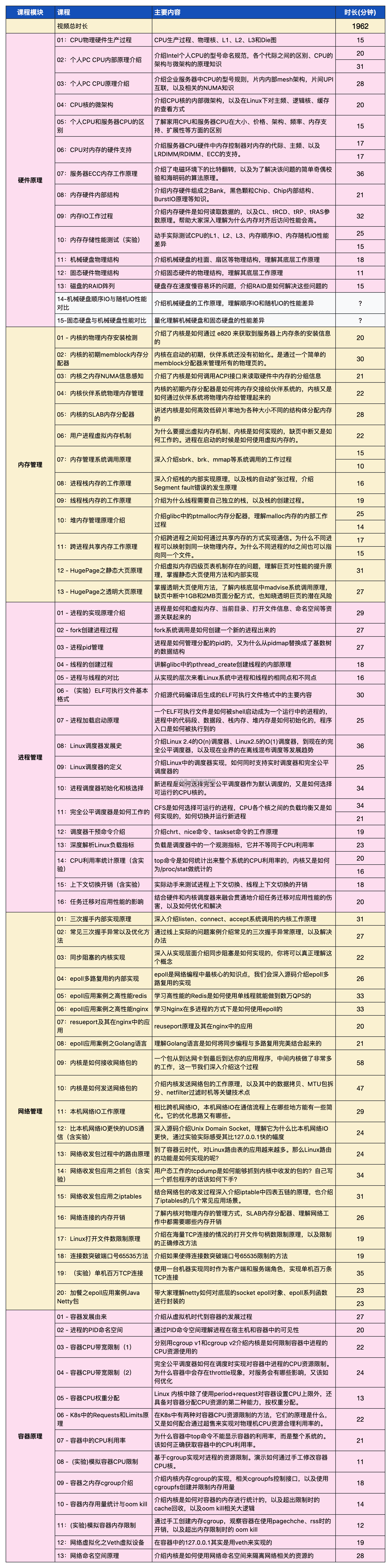
剩下各个大部分还在持续更新中。
除了视频内容,星球里我也给大家开放各种电子 PDF、PPT 的下载。
目前我给大家仍然还开放 200 元的大额优惠券。加入后一年是 299 元。后期再续费目前是 6 折,也是 299。直接使用下方优惠券加入即可看上面的这些视频内容。

