
软中断会吃掉你多少CPU?
前面的几篇文章里讨论过了进程上下文切换和系统调用对系统性能的影响,我们今天再来看另外一个CPU吃货,那就是软中断。 你在用vmstat或者其他一些工具查看系统CPU消耗的时候,发现有两列是单独列出来的,分别是是hi和si。他们分别是硬中断和软中断。既然vmstat把中断的开销单独列出来了,就...
前面的几篇文章里讨论过了进程上下文切换和系统调用对系统性能的影响,我们今天再来看另外一个CPU吃货,那就是软中断。 你在用vmstat或者其他一些工具查看系统CPU消耗的时候,发现有两列是单独列出来的,分别是是hi和si。他们分别是硬中断和软中断。既然vmstat把中断的开销单独列出来了,就...
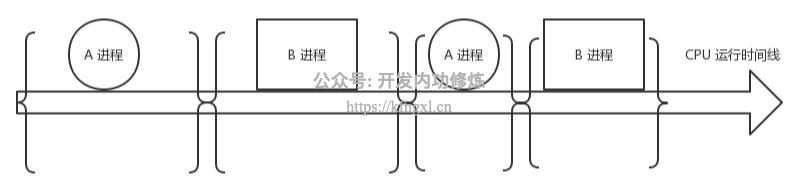
进程是操作系统的伟大发明之一,对应用程序屏蔽了CPU调度、内存管理等硬件细节,而抽象出一个进程的概念,让应用程序专心于实现自己的业务逻辑既可,而且在有限的CPU上可以“同时”进行许多个任务。但是它为用户带来方便的同时,也引入了一些额外的开销。如下图,在进程运行中间的时间里,虽然CPU也在忙于干...
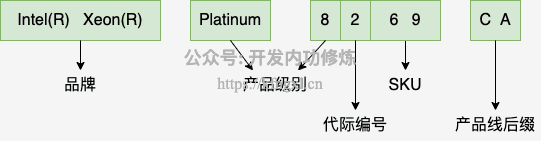
大家好,我是飞哥!在前面两篇文章《个人 CPU 的型号、代际架构与微架构》 和 《聊聊近些年 CPU 在微架构、IO 速率上的演进过程》 , 我们介绍了个人台式机电脑中的 CPU 型号规则、核设计细节,以及各代 CPU 的关键变化。在这一节中,让我们进入到和大家手头工作相关度更高的服务器 CP...

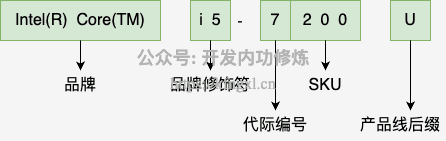
大家好,我是飞哥!在上一篇《深入了解 CPU 的型号、代际架构与微架构》 中我们介绍了我手头的一颗 Intel(R) Core(TM) i5 的型号规则,以及它的物理硬件的 Die 图结构。以及它对应的 Skylake 核的微架构实现。不少同学开始问我其它型号的 CPU 和它比有什么区别呢。考...
大家好,我是飞哥!在10月16号的时候,Intel 正式发布了第 14 代的酷睿处理器。但还有很多同学看不懂这种发布会上发布的各种 CPU 参数。借着这个时机,我给大家深入地讲讲 CPU 的型号规则、代际架构与微架构方面的知识。CPU 在整个计算机硬件中、技术体系中都算是最最重要的东西了。但很...